Documentation Index
Fetch the complete documentation index at: https://docs.brightdata.com/llms.txt
Use this file to discover all available pages before exploring further.
有问题吗?点击这里 联系我们 >>>
2026 年 5 月
⚠️ 已知问题
Grok 爬虫暂时不可用
由于 Grok 端出现拦截问题,Grok 爬虫当前暂时不可用。Bright Data 正在密切关注情况,并将在该爬虫恢复可访问后尽快重新启用。📘 文档
明确 GET /zone/cost 的 to 参数不包含结束日期
to查询参数不包含指定的日期 — 该日不计入结果。要匹配控制面板或发票上显示的某个自然月,请将to设置为下一个月的第一天。查看更新后的文档。
🚀 改进
LLM Scrapers
- 更新了 LLM Scrapers 支持的国家/地区:已修订所有 LLM scraper(ChatGPT 及其他答案引擎)的支持国家/地区列表。查看完整列表。
2026 年 3 月
✨ 新功能
Scraper:ChatGPT 新增字段
研发团队为输出 schema 新增了字段:prompt_sent_at。该字段可让客户知道 scraper 点击”发送”提交提示词的确切时间。此前我们只提供服务收到请求的时间戳,而非提示词实际执行的时间。WSAPI Google SERP - 100 条结果
- 新增
collapse_aio参数:设置collapse_aio=true可在返回的 SERP 中折叠 AI Overview (AIO) 部分。通过避免 AIO 把自然搜索结果向下推挤,使布局与像素位置测量更稳定、可比较。默认值为false(AIO 展开)。了解更多
Browser API - 会话 ID 与会话日志
2026 年 1 月
截至 2026 年 1 月 6 日当周的发布说明
✨ 新功能
Model Context Protocol (MCP)
- 自定义 MCP 配置:从 60+ 个专用选项(电子商务、社交媒体、旅游等)中仅选择必要的工具,对 AI 代理进行精细调优,从而优化性能并减少 token 消耗。内置解封与 CAPTCHA 解决能力。立即体验
- 一键连接 MCP:零配置即可立即接入 MCP 免费版。一键链接到 Claude、Cursor 或 Visual Studio Code。立即体验
✨ 新功能
Web Unlocker
- 单次调用解封带片段(fragment)的 URL:可通过 Unlocker API 直接解封包含片段(# 字符)的 URL,无需额外变通方法。
- REST API:直接提供带片段的 URL(例如
https://www.somesite.com/#!/path1/id11133/9*Fmt=100)。由于处理量增加,响应时间可能略长。 - Native API:使用新增的
x-unblock-url-fragment标头传递片段部分。了解更多
- REST API:直接提供带片段的 URL(例如
✨ 新功能
SERP API
- 支持 Google Trends:使用新增的专用参数(例如
brd_trends=timeseries,geo_map)提取趋势数据,可获取特定 widget 的数据(如时间序列与地理可视化)。支持”Trending now”,并提供地理定位、时间范围、类别与搜索类型选项。 - Google Reviews 抓取:采集 Google Reviews 数据,可完全控制定位、本地化、排序、筛选与分页。
- Google Lens 集成:通过 Google Lens 进行图像搜索。支持图像 URL、文件上传、本地化以及精确匹配筛选。
- Google Hotels 数据提取:访问酒店搜索结果,支持本地化、预订日期、客房选项以及多种输出格式。
- Google Flights 数据提取:检索航班搜索数据,提供完整的本地化支持与详尽的航班信息。了解更多
✨ 新功能
Residential 代理
- 请求保证最低会话生命周期的对等节点:使用新增的
min_ttl参数(1-60 分钟)请求预计将在线保持指定时长的住宅对等节点,特别适合 IP 变化会造成中断的长时间会话场景。
🚀 改进
代理基础设施
- 扩展 ISP 代理容量:新增约 200,000 个 ISP IP,提升 IP 池多样性,并降低高并发场景下的轮换压力。
- 更智能的数据中心负载均衡:改进了用于数据中心代理负载分配的带宽度量算法,实现更优的流量调度。
- 新增目标主机超时错误码:为”Destination host connect timeout”错误新增了专用
brd_error错误码,便于清晰区分代理与目标站点的连接问题。 - 更快的系统告警送达:优化了网络状态告警邮件通知系统,可在服务中断或恢复时及时送达。
- 增强的隧道代理日志:代理日志中新增
p_dc与p_agent字段,可更好地查看每个请求所经过的数据中心与代理,便于调试与性能分析。
🐞 Bug 修复
代理基础设施
- 修复仪表板中 IP 范围预设管理:解决了删除 IP 范围预设时 UI 未更新、加载状态未显示,以及部分预设在表格视图中不可见的问题。
- 修复错误处理时的数据不一致:解决了一处竞态条件,该问题会在解决告警错误时导致数据不一致,现在监控状态更新具有原子性且可靠。
- 改进代理 agent 错误日志:修复探针超时错误中日志记录为
[object Object]而非诊断信息的问题。错误日志现在会包含连接 ID 及相关详情。 - 修复隧道操作文档提示:在内部文档的隧道服务器操作中新增了说明性提示,包括在删除 IP 范围时检查受影响客户的指引。
⚠️ 弃用
SERP API
- Google Maps 分页参数已弃用:Google Maps 的
start与num分页参数已于 2025 年 12 月 15 日弃用。- 推荐替代方案:使用 Scrapers 的 Google Maps Scraper 以获取完整的搜索结果。
- 访问 Scraper(需要登录):
https://www.bright.cn/products/web-scraper/google-maps。了解更多
2025 年 12 月
截至 2025 年 12 月 19 日当周的发布说明
✨ 新功能
Deep Lookup
- 直接在 Deep Lookup 中丰富您自己的实体列表:您现在可以将自有实体列表导入 Deep Lookup 并直接进行丰富。无论是发现新实体还是丰富已有实体,Deep Lookup 都已成为您一站式的完整丰富平台。
✨ 新功能
Web Unlocker
- 单次调用解封带片段(fragment)的 URL:您现在可以通过 Unlocker API 直接解封包含片段(# 字符)的 URL,无需额外变通方法。了解更多
- REST API:只需提供带片段的 URL,Bright Data Unlocker 会处理其余部分。由于处理量增加,响应时间可能略长。
- Native API:使用新增的
x-unblock-url-fragment标头传递 URL 的片段部分。
✨ 新功能
Residential 代理
- 请求保证最低会话生命周期的对等节点:您现在可以请求预计将在线保持指定时长的住宅对等节点。使用新增的
min_ttl参数(1-60 分钟)来获取连接更持久的对等节点,特别适合长时间浏览器会话与多步骤抓取任务(会话中途 IP 变更会破坏您的工作流)。
✨ 新功能
SERP API
- 在 zone 设置中配置默认数据格式:您现在可以直接在 SERP API zone 配置中设置首选的默认数据格式(JSON、HTML 等)。此后无需在每次请求中指定格式标头,一次设置后所有请求都会自动使用您的首选格式。
🚀 改进
Datasets
- 结账速度最多提升 85%:以往需要 15-30 秒的数据集购买现在仅需 2-5 秒即可完成。结账延迟显著降低,购买体验更加流畅。
- 扩展电商数据覆盖:我们在主要电商数据集中显著扩充了商品目录:
- Wayfair:6M → 15M 商品(+150%)
- Amazon Global:35M → 85M 商品(+143%)
- Google Shopping:84M → 113M 商品(+35%)
- Amazon Products US:310M → 374M 商品(+20.6%)
- 更严格的校验提升数据质量:完整数据集新增了校验流程,在交付前确保更高的数据质量。该改进正在我们的数据管道中陆续上线。
🚀 改进
代理基础设施
- 扩展美国地区 ISP 代理容量:在达拉斯、洛杉矶与阿什本等关键美国地点新增逾 300,000 个 ISP IP,为高并发场景带来更高的 IP 多样性与更低的轮换压力。
- 更快加载详细统计:优化银行统计服务,消除加载详细统计报告时的超时问题,您的代理使用分析将更可靠。
- 代理池更新期间延迟降低:优化 DC 代理池处理流程,消除索引更新时的延迟峰值。即便存在后台数据刷新,您的请求也能保持稳定的低延迟。
🚀 改进
控制面板
- 统一的代理列表下载体验:我们在控制面板中统一了代理列表的下载体验。所有下载位置现在均提供一致的体验和多种格式选项:
- 冒号分隔:
host:port:usr:pwd或usr:pwd@host:port - CSV:
host,port,usr,pwd(可选位置数据) - IP 列表:单列 IP
- 冒号分隔:
- 下载文件名现在包含时间戳,可避免覆盖;下载前会显示预览。安全提示会提醒您妥善保管代理凭据。
🐞 Bug 修复
Datasets
- 修复导出时缺失丰富字段:解决了以 CSV 或 JSON 格式下载数据集时丰富字段缺失的问题。所有丰富数据现在均能正确导出,确保下载内容完整。
🐞 Bug 修复
代理基础设施
- 修复持久连接的会话掉线:解决了 const=true 的会话在对等节点临时断开时被错误地中途丢弃的问题。您的持久会话现在能在浏览器任务和长时间抓取过程中按预期保持 IP 一致性。
- 修复仪表板中 IP 范围预设管理:解决了删除 IP 范围预设时 UI 未正确更新以及部分预设在表格视图中不显示的问题。静态 IP 管理界面现在能即时反映更改。
- 修复错误处理时的数据不一致:解决了一处可能在解决告警错误时引发数据不一致的竞态条件。监控状态更新现已具有原子性,保证可靠的告警状态管理。
- 改进代理 agent 错误日志:修复探针超时错误日志记录为
[object Object]而非有效调试信息的问题。错误日志现在会包含连接 ID 及相关诊断详情,便于更快排错。
截至 2025 年 12 月 2 日当周的发布说明
🚀 改进
Browser API
扩展 C# 的 CAPTCHA 求解支持:我们为 PuppeteerSharp 与 Playwright 开发者新增了专用示例。您现在可以直接从文档复制粘贴现成代码来处理 CAPTCHA 挑战。代理网络
统一的代理列表导出:以一致体验导出代理列表。您现在可以轻松选择首选格式(CSV、TXT 或仅 IP)并自定义分隔符样式以加速集成。前往”我的代理” -> 选择代理 -> 在”概览”标签中点击”下载” -> 选择格式 -> 点击”下载”。或者,在”概览”标签中点击”查看” -> 点击”下载” -> 选择格式 -> 点击”下载”。识别异常断开:新增错误代码 client_10140 以标识”客户端粗暴断开”。您现在可以区分连接是被客户端强制终止还是网络错误,便于更快排查。🐞 Bug 修复
Web Unlocker
准确记录标头使用情况:修正了系统日志中的一处报告问题;custom_expect 字段现在能准确反映您的自定义标头或 cookie 是否被 Web Unlocker 逻辑实际使用。代理网络
更清晰的 SOCKS5 端口错误:修复了通过 SOCKS5 使用禁止端口时返回错误消息不准确的问题。您现在能获得准确反馈,便于更快调试连接串。更正 IP 分配告警:解决了一处 bug,专用住宅代理分配失败时会触发错误的邮件通知。现在分配失败时您将收到正确的告警,便于及时响应。2025 年 11 月
2025 年 10 月
截至 2025 年 10 月 31 日当周的发布说明
🆕 新功能
Scrapers
新增社交媒体 Scrapers:现在可以从 Facebook 个人主页、Reddit 个人主页 与特定社区(subreddit)内的 Reddit 帖子 采集数据。新增 YouTube Scrapers:我们新增了 YouTube 相关 scrapers,可从 YouTube Podcasts 和 YouTube Explore 页面(聚焦新闻内容)采集数据。Goodreads 评论 Scraper:新增 scraper 可从 Goodreads 采集 图书评论。代理
IP 国家/地区验证端点:您现在可以使用专用端点检查 Google 将特定 IP 地址关联到的国家/地区,便于核实请求的地理定位。浏览器自动化
网站更新时自动化脚本不再失效:即便网站重新设计页面或更改结构,您的浏览器自动化仍能继续工作。把更多时间用在数据使用上,而不是修复失效的脚本。MCP保持自动化数据彼此隔离与干净:同时运行多个 MCP 浏览器会话时,每个会话完全隔离,无数据混淆、无会话冲突,并行操作稳定可靠。🚀 改进
Scrapers
Google num=100 取消后,您的 Top-100 不再受影响:1 次请求,调用量减少 10 倍:使用 Scrapers (SERP100) 获取 Google 前 100 条结果,无需分页,设置语言/国家与深度,并返回原始 SERP HTML 用于审计。请求量最多减少 10 倍。了解更多更快、更可靠的电商数据采集:从 Amazon、Etsy 与 eBay 获取数据更快,错误与超时更少。抓取任务完成更快,结果更完整、更准确。CAPTCHA 解决更快:CAPTCHA 出现时您的请求等待时间更短。延迟降低意味着更快的数据采集与更高效的抓取操作。截至 2025 年 10 月 10 日当周的发布说明
🆕 新功能
无需任何配置即可测试 Web MCP:直接在浏览器中探索 Web MCP 的能力。无需安装或配置,可运行实时抓取测试、尝试不同目标,并在集成到工作流前立即查看结果。立即体验几分钟即可开始构建:使用专为您的工作流设计的原生 Python SDK 与 JavaScript SDK 将 Bright Data 直接集成到您的 Python 或 NodeJS 应用中。可在熟悉的语言中获得自动补全、类型提示、内置错误处理与完整示例。🚀 改进
更快找到所需的精准数据:大型数据集的筛选现在更快也更直观。可一次选择多个条件、更便捷地选择日期范围,更少点击即可定位精炼后的数据集。🐞 Bug 修复
更顺畅的筛选体验:修复了在优化数据集筛选时打断工作流的问题,包括清除选择与意外页面滚动等问题。2025 年 9 月
截至 2025 年 9 月 30 日当周的发布说明
🆕 新功能
Datasets
数据集快速筛选:常用筛选选项触手可及,可立即开始筛选。输入即可获得自动补全建议,或用自然语言描述需求,由 AI 为您构建筛选条件。自动将 Web Archive 交付到 Azure:将 Web Archive 数据直接发送到您的 Azure 存储,免去手动下载与上传。数据可直接进入您团队已经使用的云基础设施。🚀 改进
Datasets
即时理解 Dataset 字段含义:无需再猜测晦涩的字段名称。Dataset 筛选、预览与文档现在使用通俗易懂的标签清晰描述每个字段的内容,让您省去解读时间,把精力放在分析上。关于”Empty”更新不再令人困惑:当您的计划数据集刷新未发现新数据或变更时,现在会显示明确的”未检测到变更”状态,并通过邮件解释发生了什么,附带选项可触发完整刷新。Scrapers
采集所有 Amazon 评论,而不仅是基于文本的评论:获取更完整的商品口碑画像,可采集出现在图集中的评论。您的 Amazon 评论数据现在涵盖此前隐藏在轮播部分中的反馈。无需切换工具即可跟踪 scraper 任务:发起同步请求时,命令行响应中现在会包含可点击的链接,直接跳转到任务监控页面,无需手动导航或搜索任务。🐞 Bug 修复
Scrapers
采集所有 Glassdoor 评论无遗漏:修复了部分评论在采集时被跳过的问题。您的 Glassdoor 抓取任务 现在能更稳定地获取完整评论集。修复有评论的商品返回空结果的问题:解决了 Amazon scraper 在商品明显有评论时却返回空数据的问题。您的 Amazon 评论采集现在更可靠。Web Archive
大型 Web Archive 数据集搜索不再超时:Web Archive 的/webarchive/search 端点现在会立即返回 search_id。您可以查询大型数据集并实时跟踪搜索进度,不再中断。截至 2025 年 9 月 28 日当周的发布说明
🆕 新功能
几分钟内让 Web MCP 与您的 AI 工具协同工作:一站获取集成 Model Context Protocol 所需的一切,包括 Claude、ChatGPT、Cursor、LangChain 等的分步配置指南,以及社区提供的即用示例。了解更多截至 2025 年 9 月 19 日当周的发布说明
🚀 改进
更快完成账户验证(KYC):账户验证现在更直观,附带更清晰的指引与简化的分步流程。更快通过验证并访问您的账户。了解更多Google 抓取成功率提升:从 Google 采集数据时中断更少。改进的解封技术带来更稳定、更可靠的抓取表现。🐞 Bug 修复
更好的 Safari 浏览器模拟:修复了使用 Safari 浏览器配置时请求可能被检测或被阻止的问题。基于 Safari 的抓取现在更可靠。截至 2025 年 9 月 12 日当周的发布说明
🚀 改进
更可预测的无限套餐用量:无限制 Datacenter 与 ISP 套餐的公平使用上限现在按您所有 zone 合计计算,提供更大的流量分配灵活性,降低意外超额费用风险。在控制面板中更快找到所需:重新设计的导航让您更快访问 zones、datasets、scrapers 与设置。当前向所有新用户开放,现有用户将于 12 月获得访问权限。2025 年 8 月
截至 2025 年 8 月 31 日当周的发布说明
🆕 新功能
Datasets
一次筛选成千上万条记录:上传 CSV 或 JSON 文件,按大量值列表筛选数据集,无需手动输入数百个商品 ID、URL 或其他条件。非常适合批量操作以及将数据集与您现有数据进行匹配。即时查看丰富数据,先筛后买:包含附加丰富数据(如附带公司信息的 LinkedIn 个人资料)的数据集现在可立即加载并预览。可在购买前按丰富字段筛选以确认数据符合需要。Scrapers
在三大主流平台上监控电商定价:从 Coupang、Amazon 与 Walmart 采集当前价格与库存可用性,用于追踪竞争对手、验证定价策略或分析市场趋势。从 Google 抓取完整酒店数据:从基础信息(名称、位置、星级)到预订信息(价格、可用性、趋势)、住客洞察(评论、评分)与设施,全部从 Google 酒店列表 中采集。🚀 改进
Datasets
交付进度指示器:实时跟踪数据交付,通过控制面板中的实时进度更新查看数据集交付进度。不再猜测数据何时就绪。更快的 SFTP 传输:数据集传输到 SFTP 目的地的速度更快,大型数据交付的等待时间更短。告警噪音更少,信息更清晰:当出现交付问题时,您将看到一条合并的通知,包含全部细节,而不再是多条独立告警挤满仪表板。更智能的交付限流:为数据交付实现了新的速率限制器以提升稳定性,默认并发为 100 次交付,并支持按客户配置。Scrapers
更快排查 Scraper 错误:在我们的文档中查看每个 Scrapers 错误代码的明确说明。无需联系支持即可了解错误原因与修复方法。🐞 Bug 修复
Datasets
Dataset 预览表不再显示为空:修复了即使数据集包含数据,预览表也显示为空的问题。数据集样例现在每次都能正确显示。CSV 筛选可处理空行:消除了使用包含空行的 CSV 文件进行筛选时的错误。截至 2025 年 8 月 29 日当周的发布说明
🆕 新功能
中文即时支持:访问 bright.cn 时即可获得中文即时帮助。我们的 AI 助手 Sophie 用中文提供即时回答,在工作时间内可无缝转交人工客服。截至 2025 年 8 月 22 日当周的发布说明
🚀 改进
代理网络简化:通过删除较少使用的”Cache proxy”选项简化 zone 设置,让您更轻松地按需配置,避免混淆。🐞 Bug 修复
深色模式可读性更好:修复了控制面板部分内容在深色模式下难以阅读或视觉不一致的显示问题。
截至 2025 年 8 月 8 日当周的发布说明
🆕 新功能
MCP Playground:测试并使用全新的交互式 MCP playground。此功能允许您发送和接收消息来测试爬虫逻辑。立即体验防止误删账户:账户操作改为”停用”而非立即删除?您现在有 30 天的时间可以反悔并重新激活。此外,您的客户经理将主动联系您,了解原因并在您遇到问题时提供帮助。了解更多🚀 改进
正式集成前先免费测试任意 API:在控制面板中免费试用代理网络、Web Unlocker 与 SERP API!在编写集成代码前即可验证使用场景并查看真实结果。立即体验一键直达人工支持:当您请求与人沟通时,BrightAI 现在会提供直达链接以创建支持工单,确保您的问题获得妥善关注与跟踪,避免淹没在对话中。2025 年 7 月
截至 2025 年 7 月 29 日当周的发布说明
🆕 新功能
已验证账户的 IP 订单
可订购大量专用 IP,并支持处理时间与交付跟踪。阅读更多Deep Lookup 预览模式
在拉取数据之前可免费预览表结构,并附带内置 co-pilot 优化提示以提升准确性。阅读更多Google 轻量解析器
可将前 10 条搜索结果解析速度提升至 2.5×。阅读更多Bing → Bright Data SERP API 迁移
提供 1 对 1 的迁移路径,便于将 Bing API 解析迁移到 Bright Data 的 SERP API。阅读更多截至 2025 年 7 月 22 日当周的发布说明
🆕 新功能
Scrapers – Gemini/Grok/Google AIO
新增多模型 AI Scraper 支持,使使用任意一个模型的用户都能轻松使用其他模型。阅读更多BrightAI 起始页
推出 BrightAI —— 基于 RAG 的助手,利用账户日志与设置引导用户进行配置、优化与浏览 Bright Data 工具。数据与数据速率概览
Zone Dashboard 新增筛选器,可按 zone、类型、目标域名查看流量与连接速度,以帮助优化与检测异常。阅读更多Residential Mega Pool
提供更大的 IPv4/IPv6 住宅代理轮换池访问。IPv6 → IPv4 回退
当目标网站不支持 IPv6 时自动回退至 IPv4,以提升成功率。数据中心与 ISP 批量订单
特定客户可提前下单未来的专用数据中心与静态住宅代理,并在控制面板中查看交付进度。MCP 云存储
可选择云托管或本地部署 MCP,以获得更广泛的兼容性。阅读更多Web Archive 前缀自定义
可自定义导出文件夹路径的前缀。阅读更多2025年5月
🆕 新功能
居民网络:IPv6 支持
现在您可以在 Bright Data 的居民网络上使用 IPv6。拥有超过 150,000 个支持 IPv6 的节点,并且还在增长,此升级提供更高的可扩展性和更大的 IP 池访问。 阅读更多自定义抓取器
轻松从任何网站提取数据——无需编码或基础设施。只需提供目标 URL 并定义所需数据。可以选择自行管理项目,或让我们提供端到端服务。阅读更多抓取器:自定义字段选择
通过使用简单的管道分隔列表,仅选择所需字段,从而节省存储并简化输出。阅读更多🚀 新集成
LangChain
使用实时匿名网页数据为 LLM 代理提供动力。阅读更多Lindy.ai
使 AI “员工”能够利用实时网页数据自动执行任务。阅读更多LlamaIndex
无缝将网页数据导入和索引到知识库,以实现强大的检索增强生成(RAG)工作流。阅读更多Make
自动化抓取、数据集检索和 API 调用——无需代码。阅读更多n8n
构建自动化工作流,将 Bright Data 的功能与数百个其他应用和服务连接——全部通过可视化编辑器。阅读更多2025 年 4 月
截至 2025 年 3 月 20 日当周的发布说明
数据集
🆕 新功能
大型数据集分片与 UI 下载:可直接在 UI 下载大型数据集。大文件会自动拆分成多个小文件,并通过邮件提供下载链接。🚀 改进
- 改进的交付系统:优化后端以实现更快、更稳定的数据集交付。
- Filter API 微调:改进性能与过滤准确性。
- 支持免费数据集:新增对免费数据集的账单端支持,便于获取免费提供的数据。
错误状态文档更新
文档新增 Dataset API 错误状态码,帮助开发者更快排查问题。👉 查看文档
通过邮件下载大型快照
快照大于 5GB 时,可通过邮件接收下载链接。Snapshot Metadata API 更新
现在会返回错误详情、错误代码与启动类型,以提升可见性。🐞 修复
- 修复“自定义数据集”按钮。
- 修复大型 Parquet 文件交付时的内存错误。
- 修复过滤器缺失“list exact match”和“include”选项。
- 修复 Enriched Employee Business 数据集过滤问题。
- 修复不清晰的 UI 错误提示。
- 修复快照表某些空列显示问题。
2025 年 3 月
截至 2025 年 3 月 20 日当周的发布说明
通用:
🆕 新功能
- AI 驱动的支持
- BrightAI 现在为中小型和新客户提供支持工单的首轮响应,在确保服务质量的同时提供即时协助。您将获得更快的初始回应,但如果需要,您可以在任何时候请求人工支持专家加入对话。
数据集:
🆕 新功能
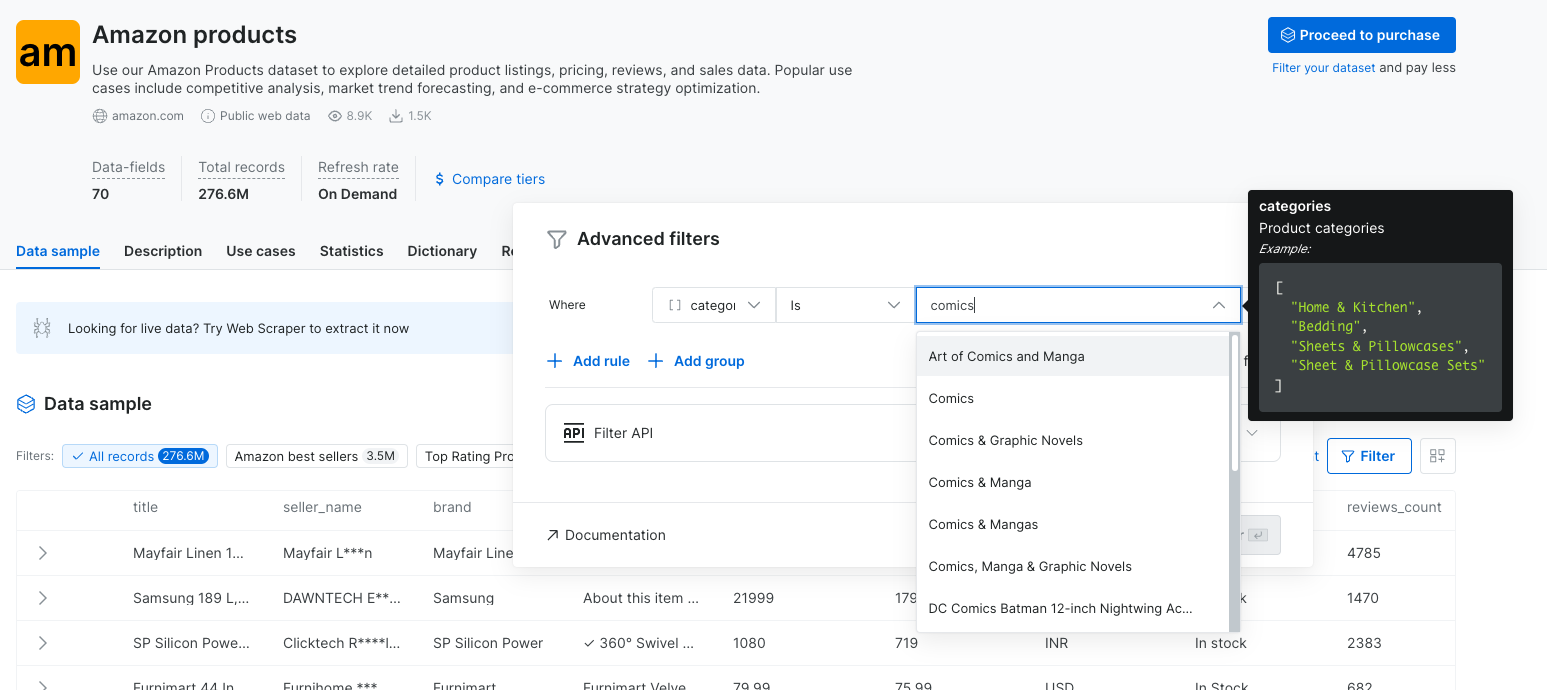
-
自动完成带来的更轻松过滤体验
-
使用自动完成建议后,过滤数据集变得更快速、更直观。例如,在选择 Amazon 类别时,您现在可以从预定义列表中选择,而无需在 Amazon 上手动搜索。
-
使用自动完成建议后,过滤数据集变得更快速、更直观。例如,在选择 Amazon 类别时,您现在可以从预定义列表中选择,而无需在 Amazon 上手动搜索。
-
新的数据集元数据 API
- 开发者现在可以通过 API 访问数据集的元数据,更轻松地与 Zapier、Make.com 和 n8n.io 等自动化工具集成。这允许您获取数据集详情和 schema,以设置自动化工作流并获取所需的精确数据。👉 查看 API 文档(link)
🚀 改进
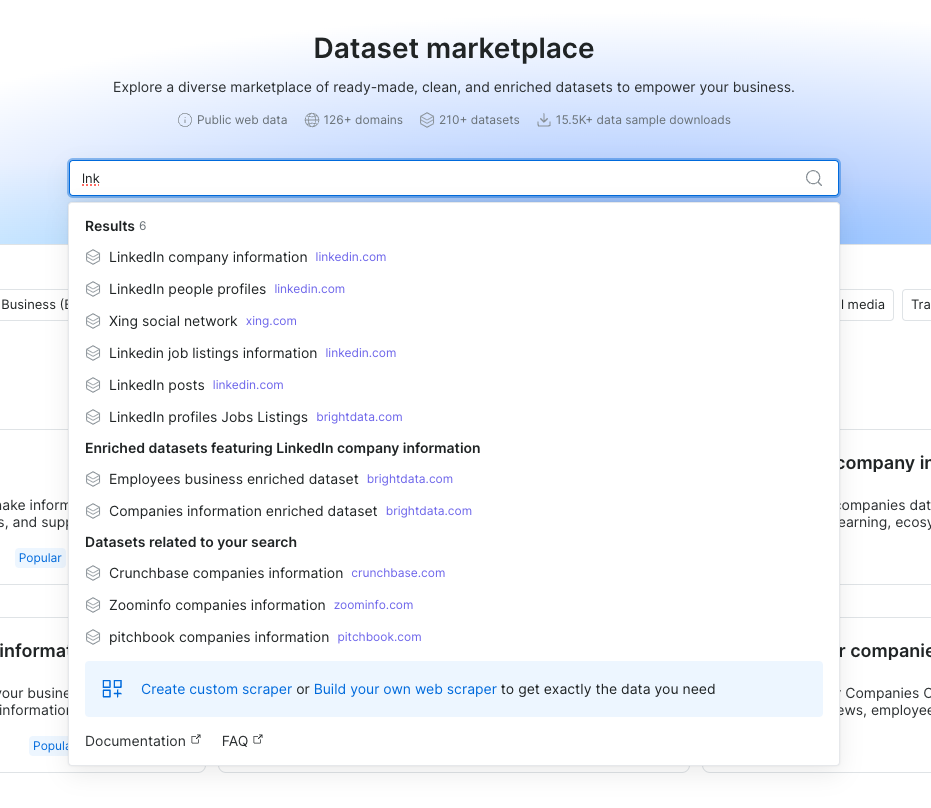
-
更好的市场搜索
-
市场中的数据集搜索现在更灵活,允许轻微的拼写错误或变体,使您在搜索不够精准时仍能找到所需内容。
-
市场中的数据集搜索现在更灵活,允许轻微的拼写错误或变体,使您在搜索不够精准时仍能找到所需内容。
-
更清晰的过滤限制提示
-
当达到每日过滤限制时,现在会显示清晰的信息说明限制及下一步操作。您还可以提交请求,让我们的数据专家协助优化过滤条件。

-
当达到每日过滤限制时,现在会显示清晰的信息说明限制及下一步操作。您还可以提交请求,让我们的数据专家协助优化过滤条件。
-
日期列的实用提示
-
日期列现在包含解释日期格式的提示,确保您理解所选日期范围内的记录是“包含”的。

-
日期列现在包含解释日期格式的提示,确保您理解所选日期范围内的记录是“包含”的。
🐞 Bug 修复
- 更好的可用性与 UI
- 我们通过修正文案错误等方式进行了一系列设计和可用性改进,让体验更加顺畅。
Scrapers(网页采集器):
🆕 新功能
-
新的端点支持同步请求获取采集数据
- 我们推出了一个新的端点,允许同步调用直接从请求来源获取采集数据,提高效率、简化流程。这一增强与未来即将发布的设计更新结合,将使用户更快访问和测试他们的采集数据,并更好地呈现其潜在价值(link)
-
新的“Wikipedia 文章”采集器
- 用户现在可以根据关键词发现和采集 Wikipedia 文章信息。
🚀 改进
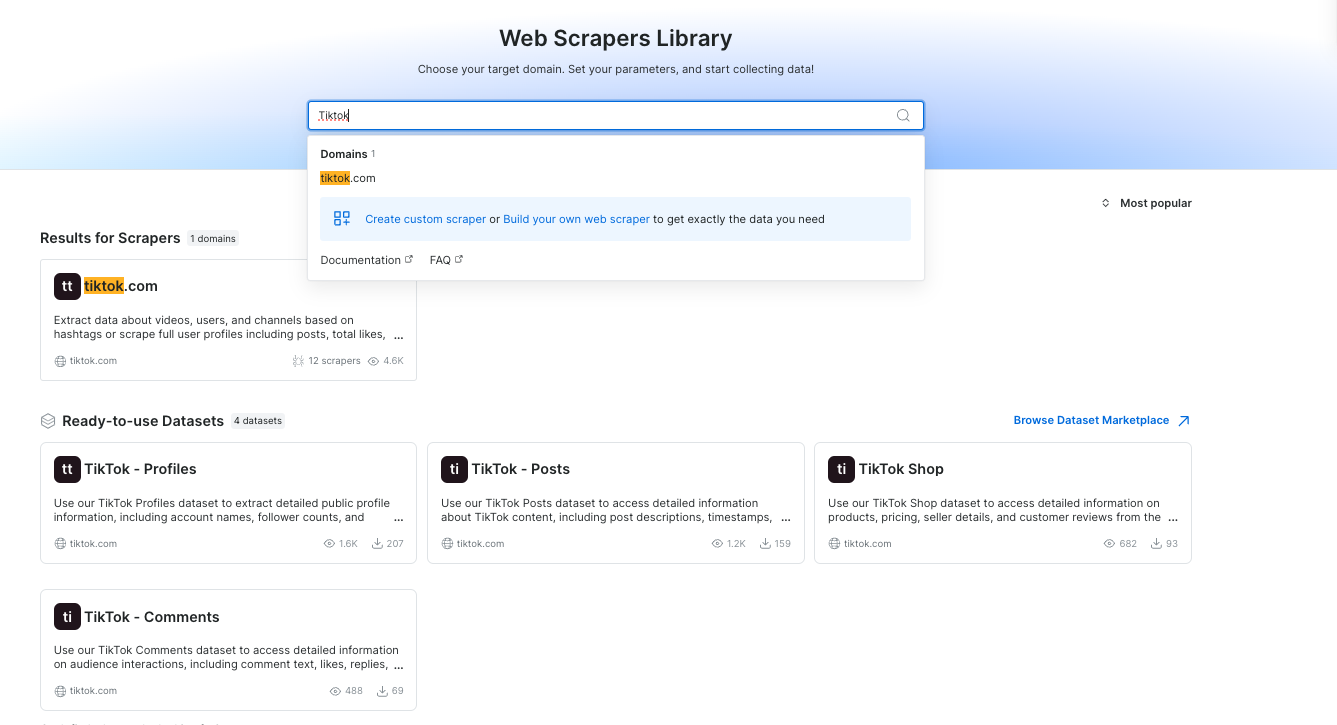
-
搜索与导航
-
我们对搜索结果和导航进行了多项改进,使用户更容易找到相关数据并探索相关产品。搜索结果现在将优先显示仅域名结果以提高准确性。此外,数据集(DS)结果将显示在 Scraper 结果下方,反之亦然,使结构更清晰。
-
我们对搜索结果和导航进行了多项改进,使用户更容易找到相关数据并探索相关产品。搜索结果现在将优先显示仅域名结果以提高准确性。此外,数据集(DS)结果将显示在 Scraper 结果下方,反之亦然,使结构更清晰。
-
SERP 中的新横幅,用于重定向对 ChatGPT 和 Perplexity 结果感兴趣的用户
-
此横幅让用户更轻松访问 AI 驱动的搜索结果数据。
-
此横幅让用户更轻松访问 AI 驱动的搜索结果数据。
🐞 Bug 修复
-
API Key 刷新修复
- 我们解决了影响 API Key 刷新的问题,确保身份验证与会话持续不受影响。
-
Scraper 请求调度通知修复
- 解决了新自定义 Scraper 请求的调度通知未正确触发的问题,确保相关人员能及时收到提醒。
截至 2025 年 3 月 13 日当周的发布说明
Web Archive API:
🚀 改进
- 热存储时长更新 Web Archive API 现在提供 72 小时的热存储数据(之前为 96 小时)。更多详情请查看此处
Scrapers:
🆕 新功能
-
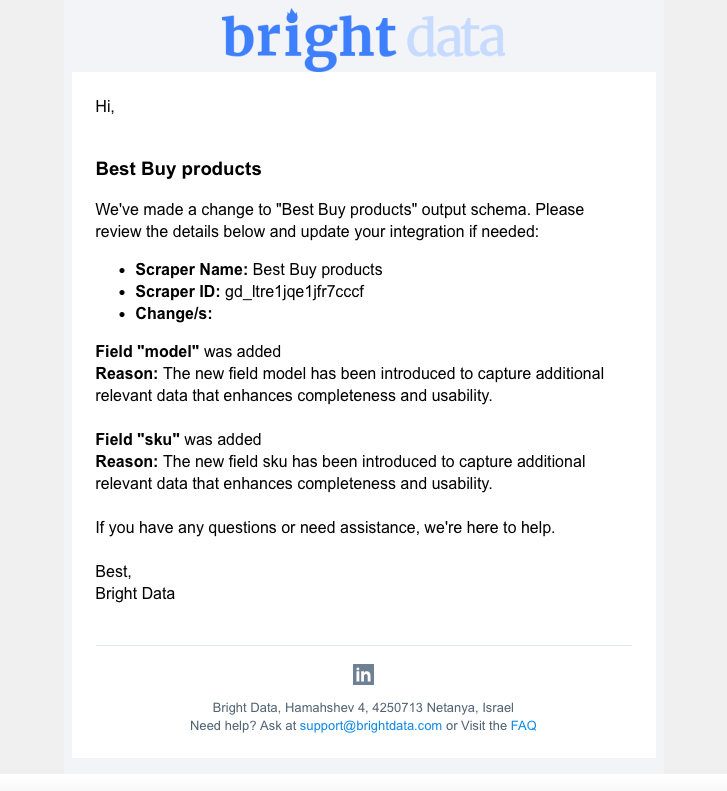
输出 Schema 更改监控
我们发布了“输出 schema 变化监控系统”,以提高检测准确性与透明度。Schema 更改通知现在整合为一封邮件推送给用户。
- 新的 Walmart 产品发现方式 用户现在可以根据 SKU 发现并采集产品信息。
🚀 改进
- 大型文件的外部存储选项 如果压缩文件仍超过 5GB,系统会提示将文件发送到外部存储,便于访问与管理。
- 自定义采集器——请求流程改进 根据客户类型(Community、Named、Key、Strategic)对请求进行分流,并仅邀请相关人员参与,提高效率。
- 自定义采集器 schema 更新更灵活 如果客户在通话中修改 schema,团队现在可在发送给合作伙伴前进行更新。
Proxy 产品:
🚀 改进
- 允许将数据中心和 ISP 代理从旧的“按 GB 计费”方案迁移到新的“无限流量”方案。
🐞 Bug 修复
- 修复住宅代理网络中默认国家的错误国家分配问题。
数据集:
🆕 新功能
-
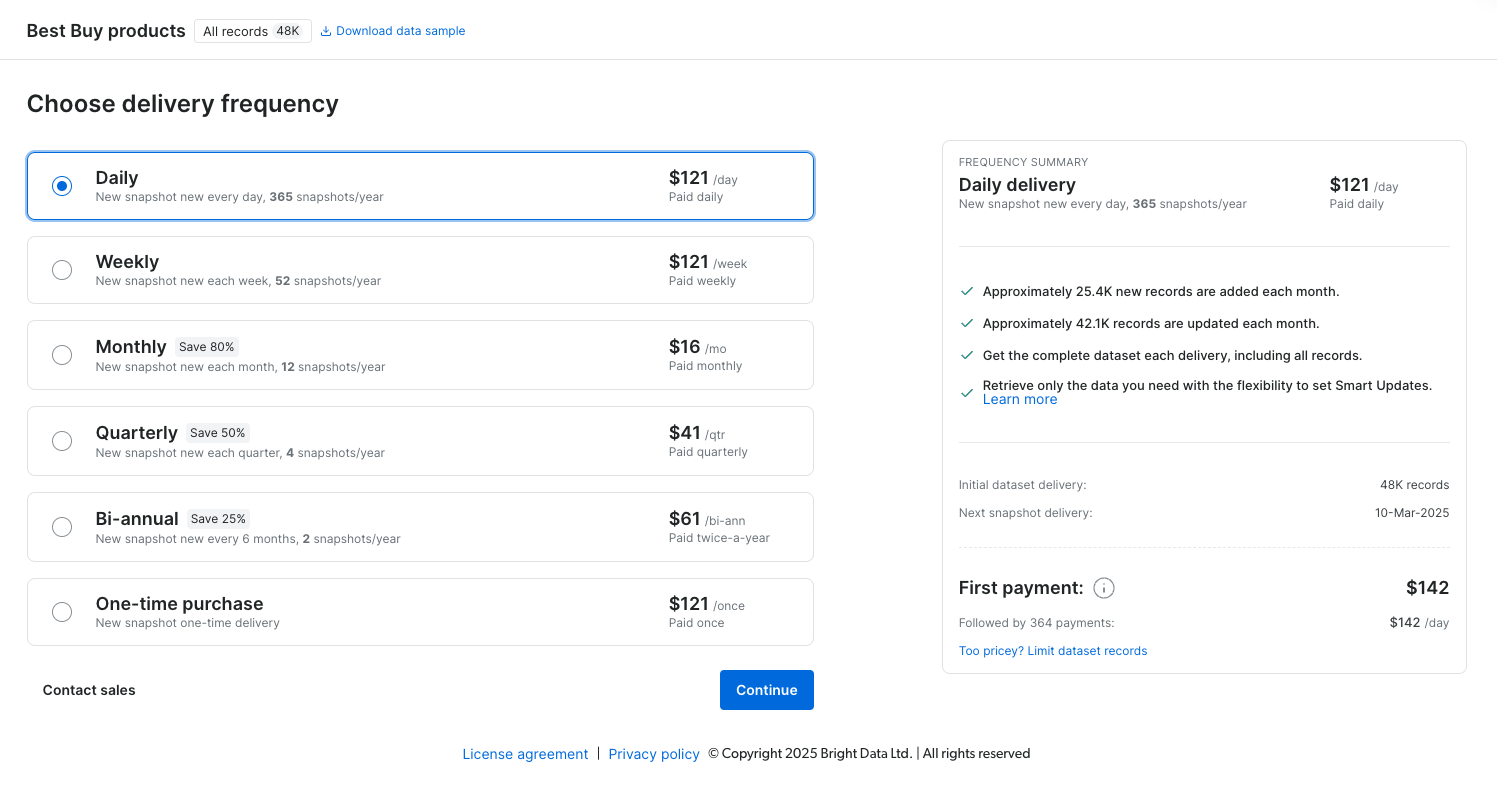
电商数据集支持每日 & 每周订阅
您现在可以为 73 个电商数据集中的 41 个设置每日或每周更新,更轻松监控新品或价格变化。
-
更好的过滤功能
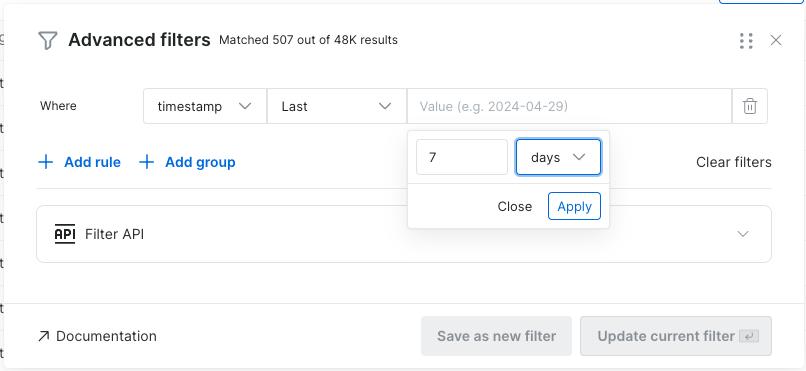
- 应用过滤器前查看匹配记录数——您现在可以在应用过滤器前看到有多少记录匹配条件。
-
按日期过滤——现在可使用相对日期进行更精准的数据选择。
-
数据集页面新增预计费用标签
- 在购买按钮下方新增预计费用标签,让您在购买前了解价格。
-
“过滤数据集”按钮可快速调整数据集筛选条件。
-
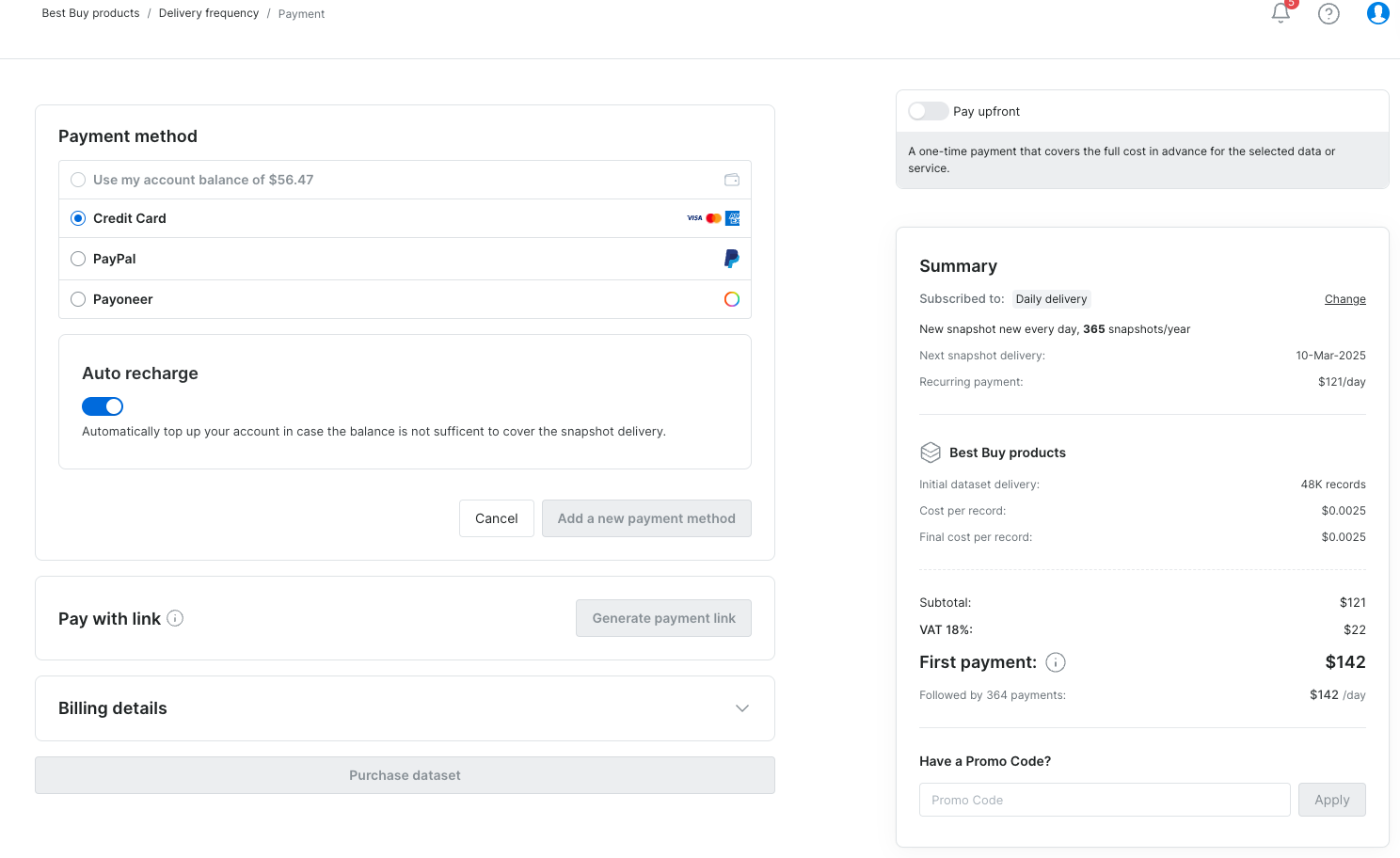
更顺畅的结账体验
- 更清晰的导航——新增面包屑导航。
- 更智能的更新说明——更好地解释 delta(增量)订阅。
-
支持优惠码——现在可在结账时直接输入折扣码。
-
更好的市场体验
- 市场中新增面包屑导航。
-
更新了头部、分类列表和数据集卡片网格,使浏览更轻松。
🐞 Bug 修复
- 更快的报价计算 通过移除不必要的计算提高了结账性能。
- 订阅更新修复 更新订阅时不再跳转到其他页面。
- 预览速度改进 数据集预览加载速度更快。
Scrapers:
🆕 新功能
- 从 No-Code Scraper 取消快照——用户现在可以直接取消正在运行的快照。
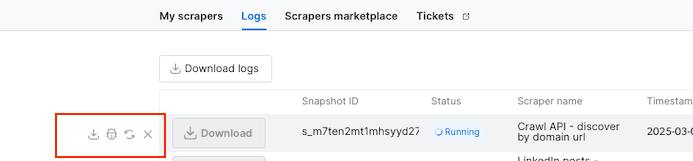
-
新的日志功能——日志区域新增按钮以提供更好的交互和调试体验。
- 新的 Airbnb 房源发现方式——根据过滤后的 URL 获取房源信息。
- 新的 Glassdoor 公司发现方式——根据过滤后的 URL 获取公司信息。
🚀 改进
Scrapers 首页 UI 增强我们改进了 Scrapers 首页的可用性,包括更快的搜索、更紧凑的卡片显示、更多推荐内容、更智能的自定义 Scraper 建议,以及分类页面内的搜索功能。
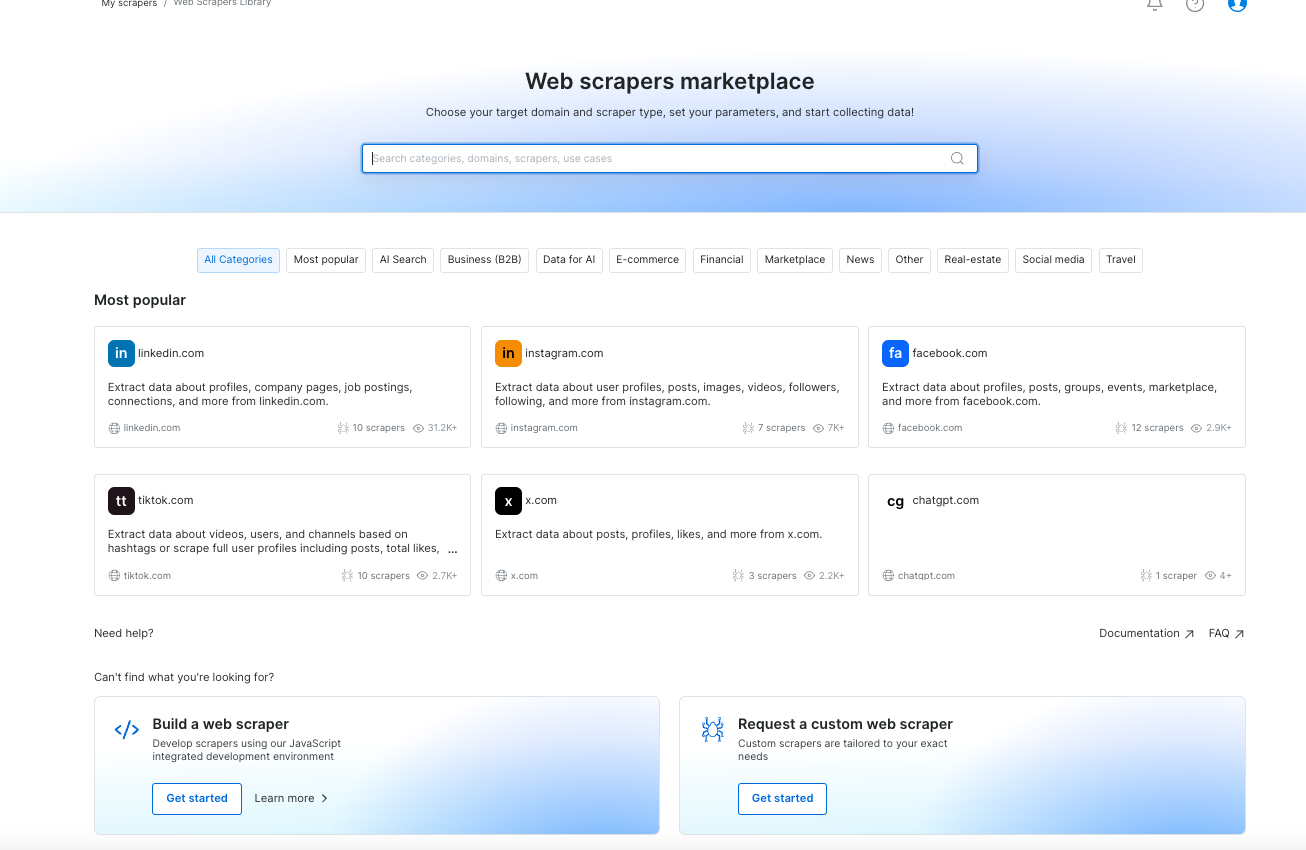
- 统一 API 与 No-Code 的数据交付选项 修复了 API 与 No-Code Scraper 在数据交付设置上的不一致,使配置逻辑统一。
🐞 Bug 修复
- 修复损坏的数据交付设置
- 过滤功能修复——“我的采集器”表格过滤现在可按产品正确工作
- URL 结构统一——所有 Scraper URL 现在遵循统一格式,包含
scrapers - Scraper 首页搜索结果修复
2025年2月
代理产品:
🚀 改进
-
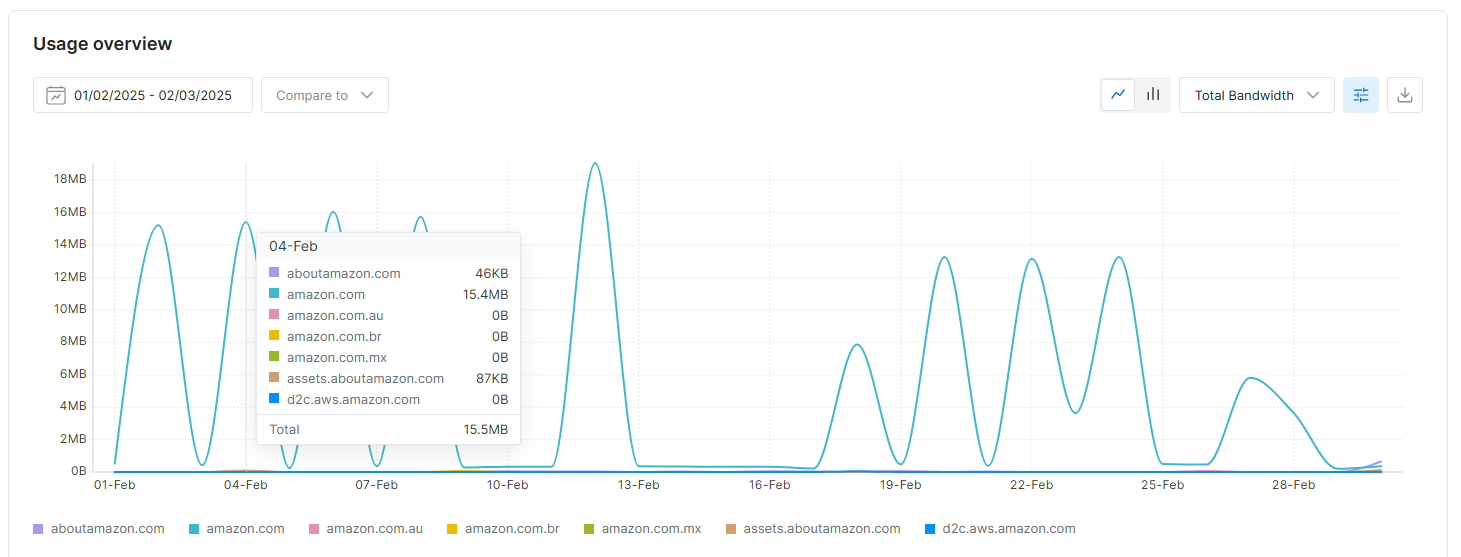
在区域概览页面中新增按域名分解区域统计数据的选项:
Unlocker API:
🆕 新功能
- 现在您可以将 HTML 自动转换为 Markdown 语言。此功能同时支持 API 和原生代理接口。请参见 https://docs.brightdata.com/cn/scraping-automation/web-unlocker/features#以-markdown-抓取
数据集:
🆕 新功能
-
支持数据集过滤器中的日期表达式:现在您可以在数据集过滤器中使用日期表达式(相对日期),便于根据时间条件精细选择数据。此功能同时支持 Filter API 和数据集订阅,允许更灵活的动态过滤。示例用例:假设您希望过滤记录,仅包含过去 7 天的数据。可以使用“最近”表达式检索过去一周的所有记录,同时排除更早的数据。

🚀 改进
- 我们增强了个人可识别信息(PII)的屏蔽方式,以提高数据安全性和合规性。
- 改进结账页面报价生成时间——加载报价数据和最终价格的时间更快。
- 发布了新的结账页面,用户现在可以直接在结账页面查看已添加和更新的记录。
🐞 错误修复
- 修复预览表错误:解决了导致数据集预览表加载缓慢的问题,确保数据预览更快速顺畅。
抓取器:
🆕 新功能
-
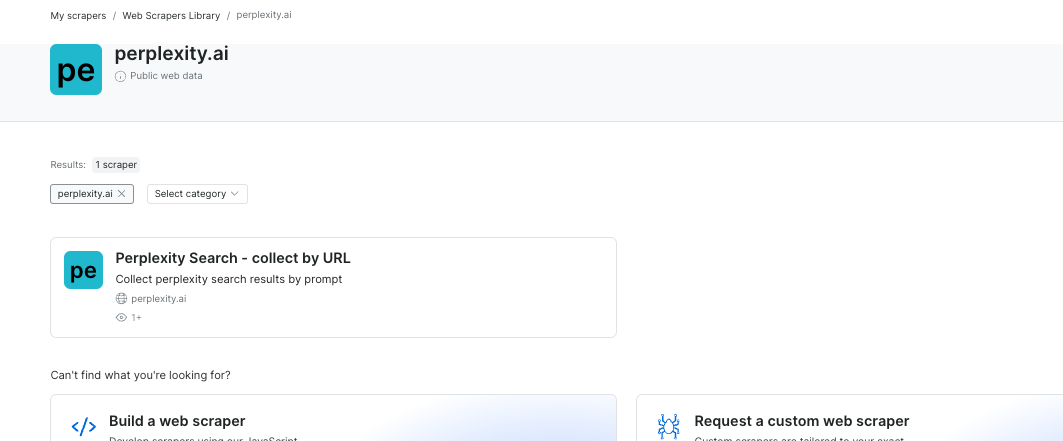
Perplexity 抓取器 - 推出全新 Perplexity 抓取器,类似于我们的 ChatGPT 抓取器!此抓取器允许客户以编程方式与 Perplexity 交互,将响应作为结构化数据检索。现在,您可以轻松自动化查询并从 Perplexity 提取洞见。在此尝试
- 模式变更监控系统 – 实施了首个模式变更监控与告警系统,以提高数据准确性和稳定性。它能够检测更改并发送自动通知,确保数据操作无缝进行。预计未来几周系统将进一步改进。
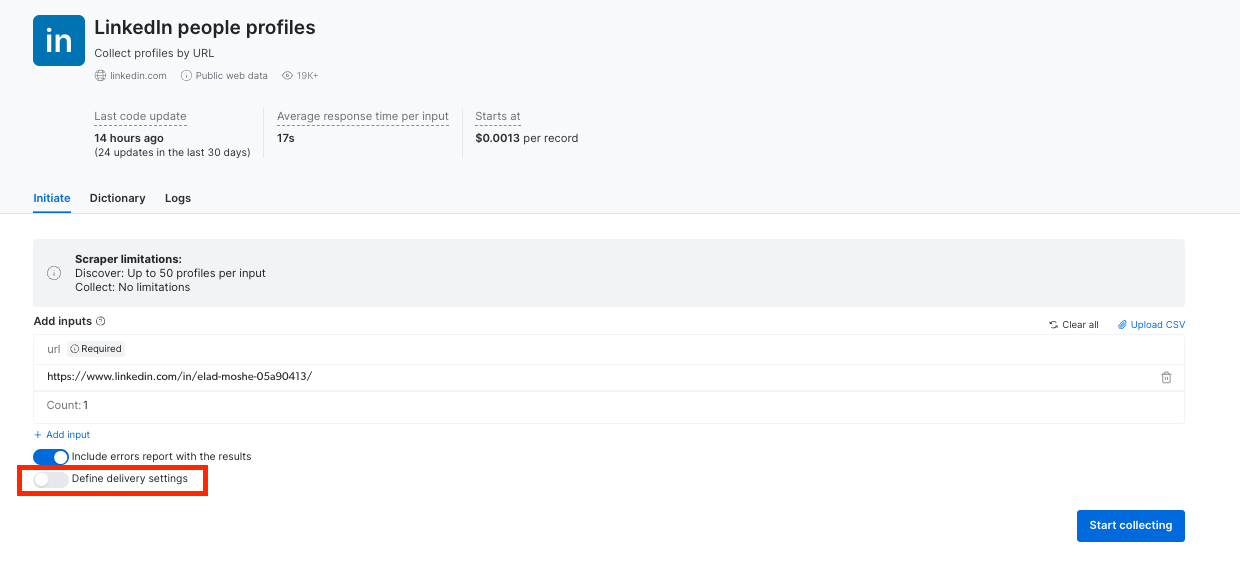
-
无代码抓取器新交付功能 – 我们新增了交付方式,为无代码用户提供更多导出和访问抓取数据的灵活性。
🚀 改进
-
增强搜索选项以包含新结果类型 – 搜索功能现在显示数据点及其对应的抓取器,使用户更容易根据输出识别相关抓取器。
- “交付到外部存储”默认启用 – 为简化工作流程,Web 抓取器 API 现在默认启用外部存储交付,减少手动设置步骤。
- 自定义抓取器请求 - 简化了请求流程。现在只需两个 URL,其余部分将自动处理,从而优化请求过程。
🐞 错误修复
- 解决影响自定义抓取器的问题,并实施告警系统,当需要操作时通知合作伙伴。
- 修复未定义 URL 结构——改进 URL 处理以确保不同页面结构一致且清晰。
代理产品:
🆕 新功能
- 新 API 将提前提供待替换代理列表并进行准备。获取待替换代理 API
🚀 改进
- 使用预制连接字符串(host、port、user 和 password)更快速地集成代理访问详情,并配有新配置指南 集成指南。
- 我们在错误目录中新增错误代码。通过 代理错误目录 更快地查找并自行解决问题。
- 我们在亚洲增加了服务器部署,并提升了一些性能。
SERP API:
🆕 新功能
- 谷歌生成式 AI 概览 - 现在可以提高该概览在 SERP 结果中出现的概率:
- 谷歌趋势 - 新参数可获取更准确的小部件特定数据:
- `brd_trends = timeseries,geo_map`
- https://docs.brightdata.com/cn/scraping-automation/serp-api/query-parameters/google#trends
数据集:
🆕 新功能
-
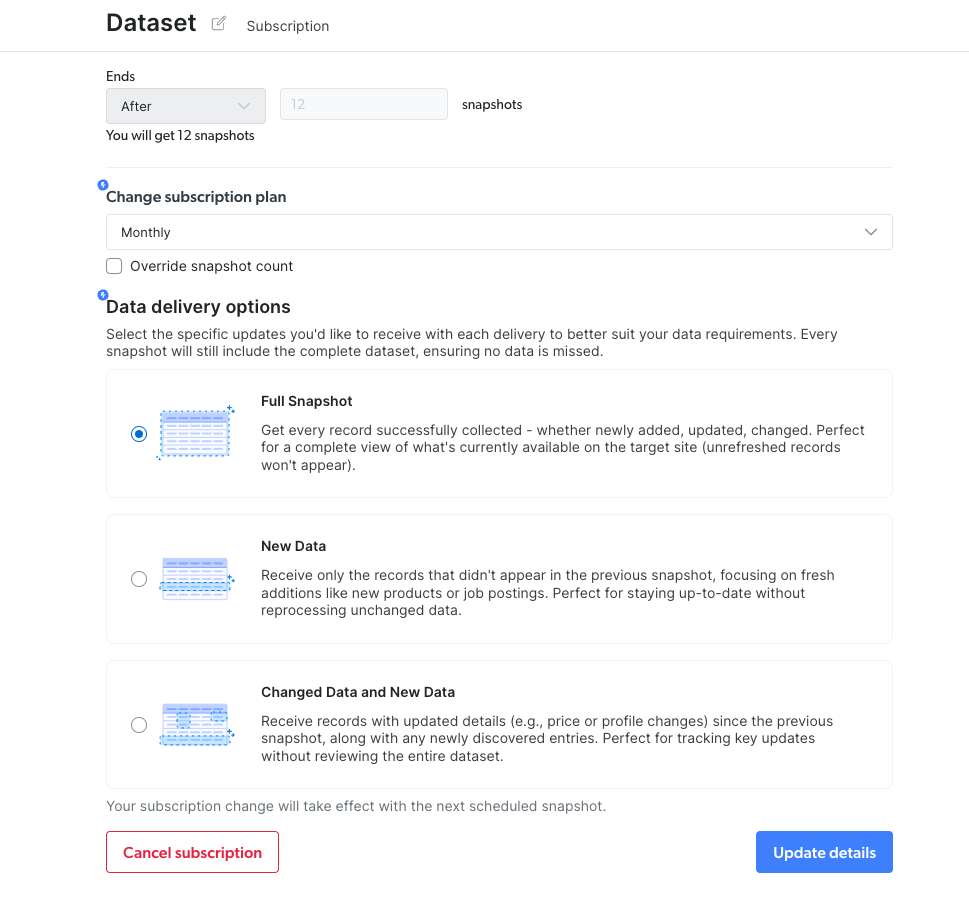
数据集订阅增量数据 - 客户现在可以启用增量逻辑,只接收新增或更新的记录,而非每个收集周期的完整数据集。此功能提高数据相关性,并允许灵活的快照比较。无需手动识别更改,我们的系统会自动处理。
🚀 改进
- 新定价表 - 重新设计的定价表提供更清晰信息,便于客户理解定价等级并做出明智决策。
- 增强数据集结账确认页面 - 修复确认页面以确保结账体验更加顺畅可靠。
- 改进缺少支付信息的错误提示 - 尝试购买但未添加支付和账单信息的客户将收到更清晰、信息更丰富的错误提示。
- 优化交付方式 - 调整交付选项顺序,并对界面进行改进以提高可用性。
- “更新数据集”键盘快捷键 - 新增键盘快捷键以简化数据集更新及界面操作,提升用户体验。
- 改进数据样本预览表 - 用户现在可以直观展开表行,并在弹出窗口中查看对象数据类型,以获得更清晰的可视化效果。
🐞 错误修复
- 修复路由错误 - 导航数据集页面时不再保留不必要的查询参数。
- 修复促销卡 UI 问题 - 促销卡现已按预期布局正确显示。
抓取器:
🆕 新功能
-
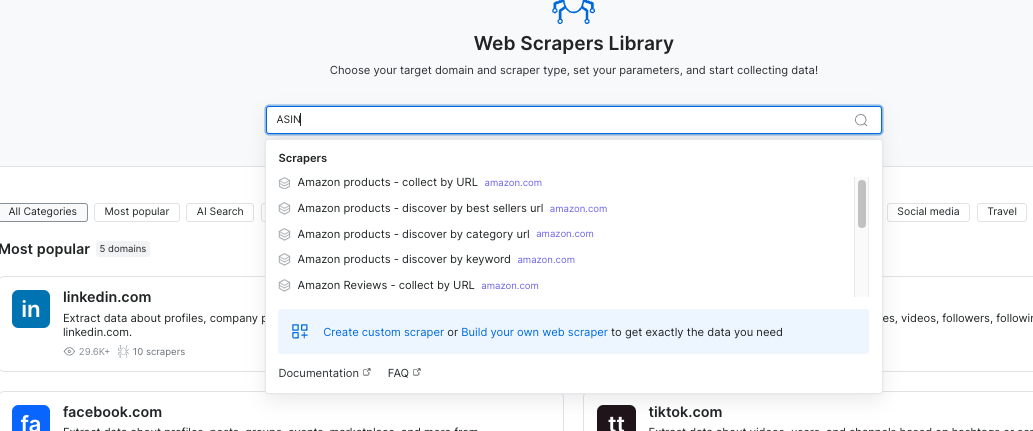
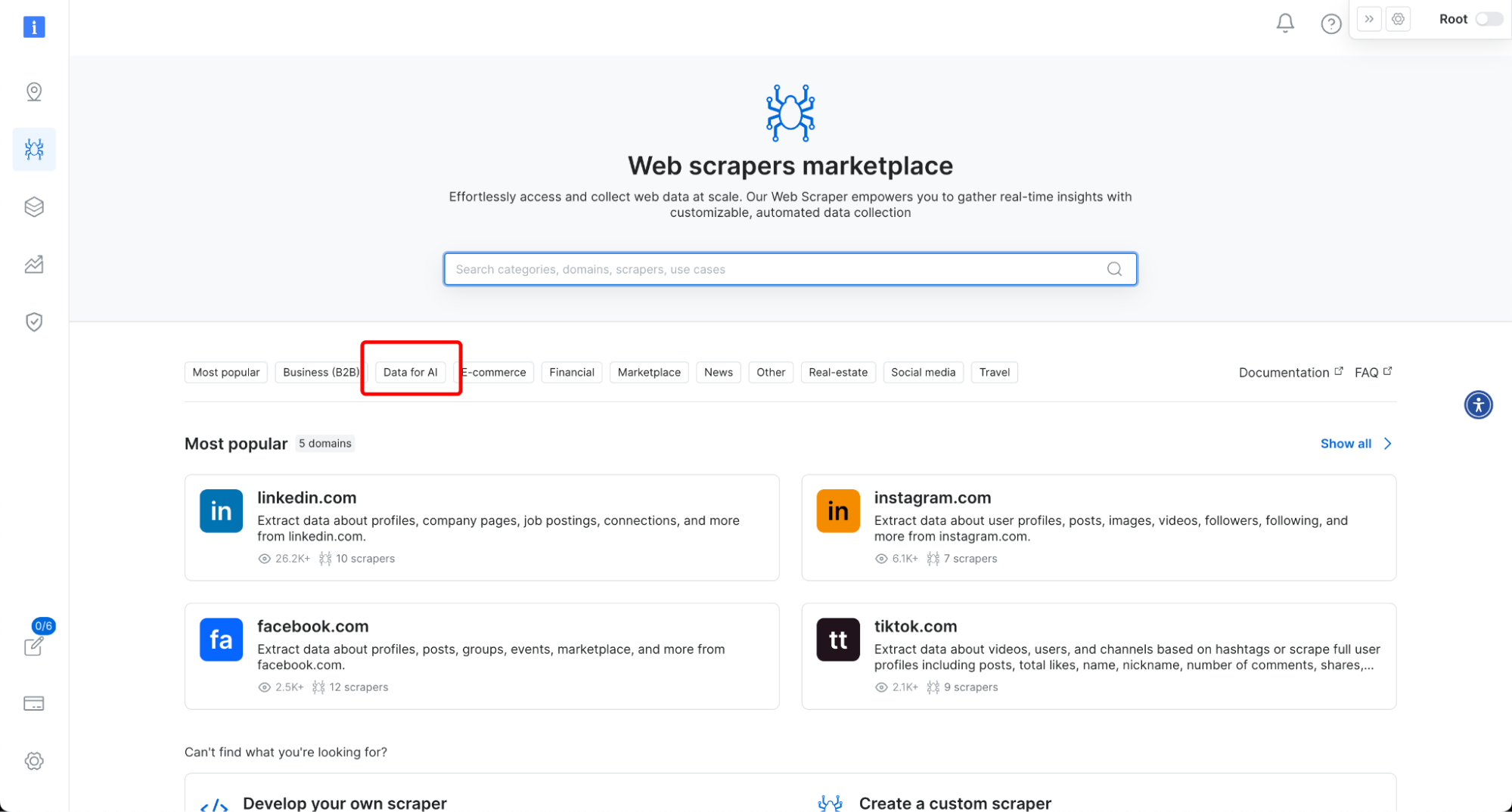
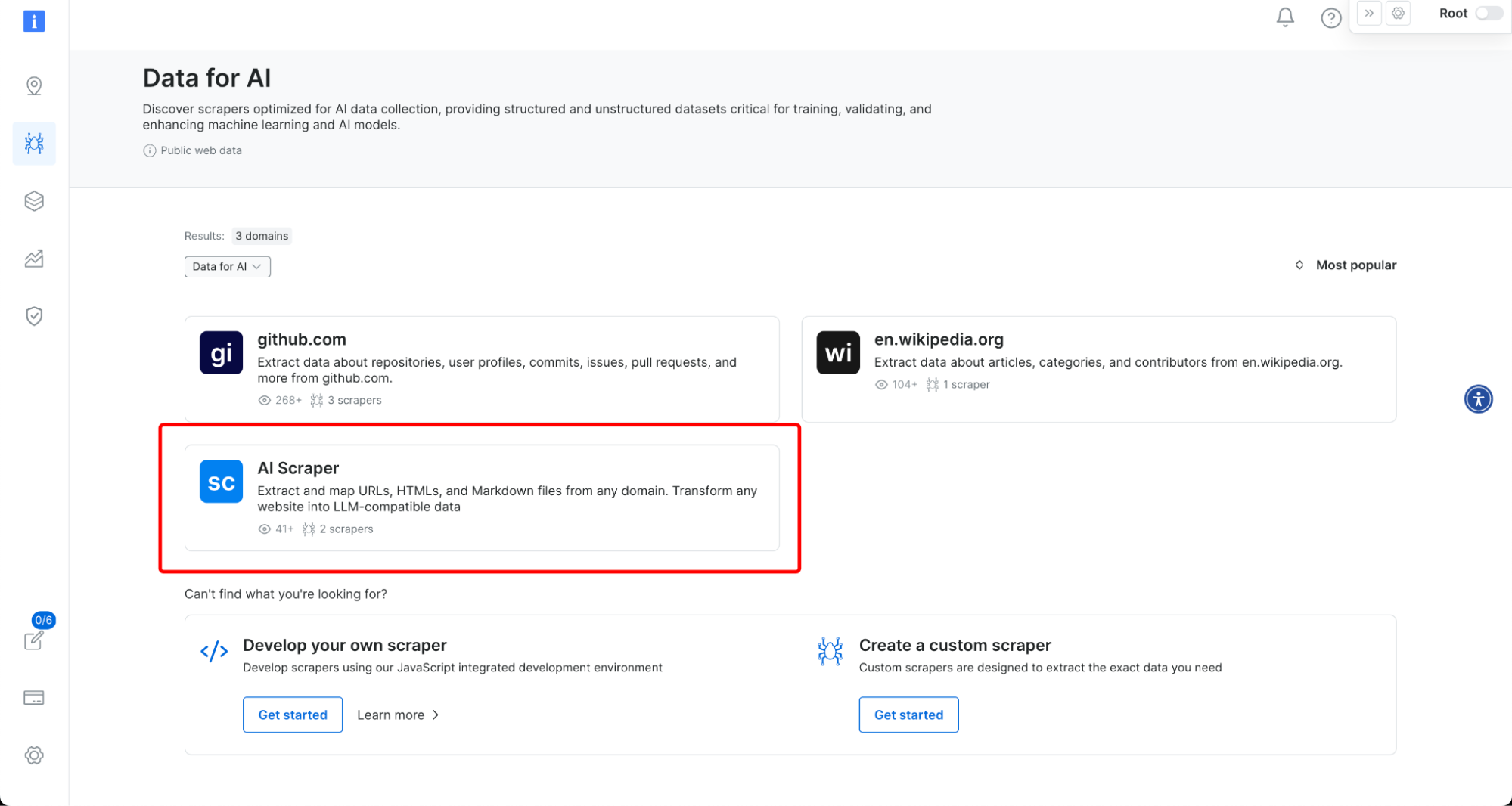
AI 抓取器代理 – 首个 AI 抓取器代理允许用户仅提供域名即可提取任何网站的数据。它会自动检索该域名下的所有 URL,并以 HTML、Markdown 或纯文本格式提取内容。适用于 AI 公司、研究人员和开发人员,需要高质量文本数据进行模型训练、分析或内容生成。在此尝试
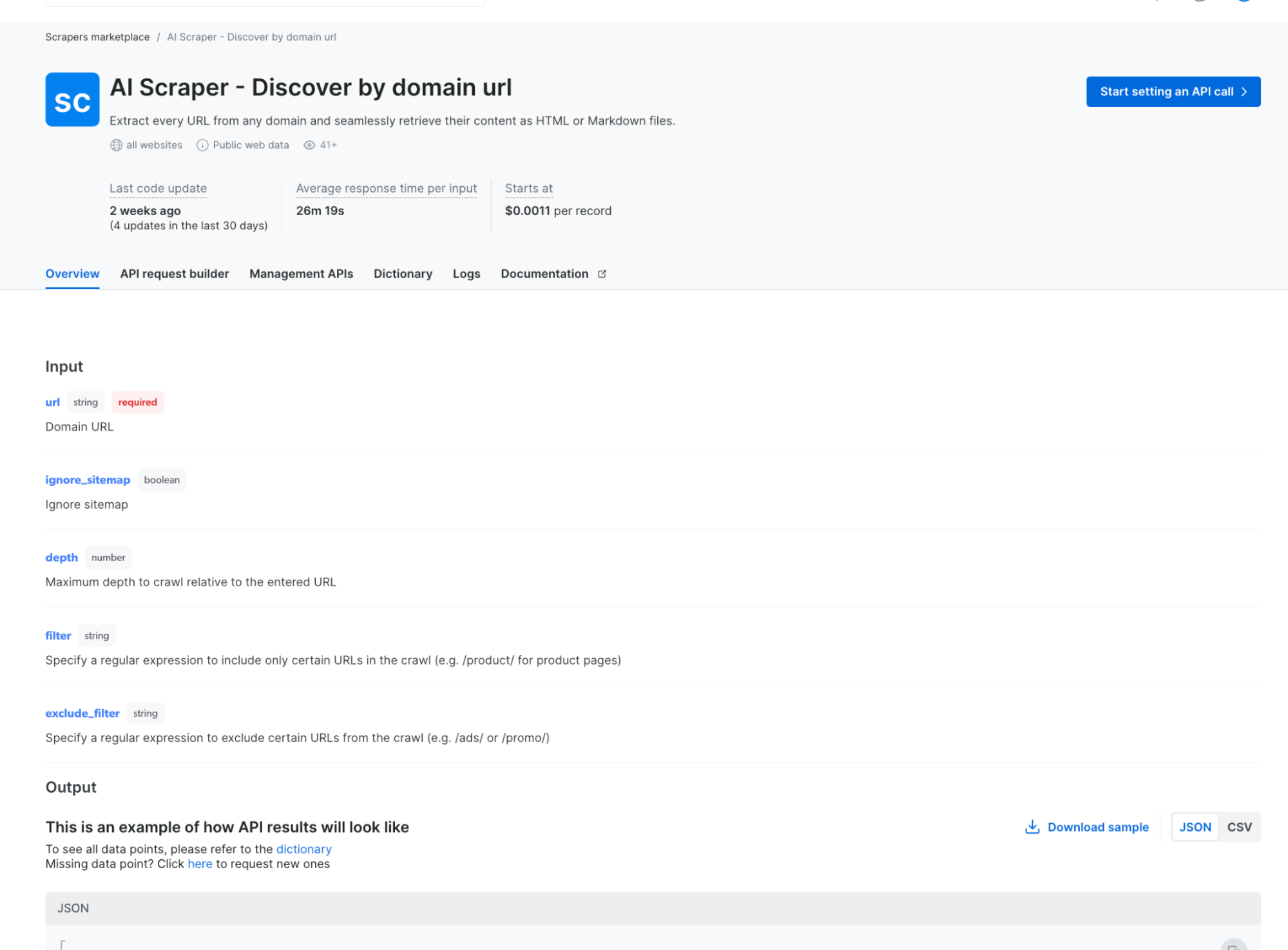
-
ChatGPT 抓取器 - 推出全新 ChatGPT 抓取器,类似于我们的 SERP 抓取器!此抓取器允许客户以编程方式与 ChatGPT 交互,将响应作为结构化数据检索。现在,您可以轻松自动化查询并从 ChatGPT 提取洞见。在此尝试
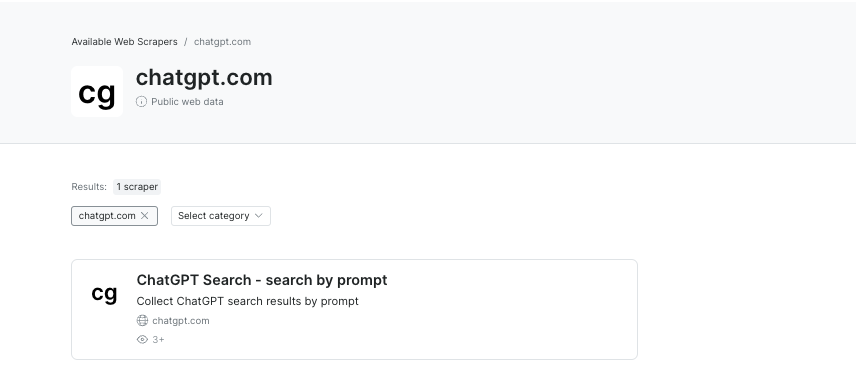
-
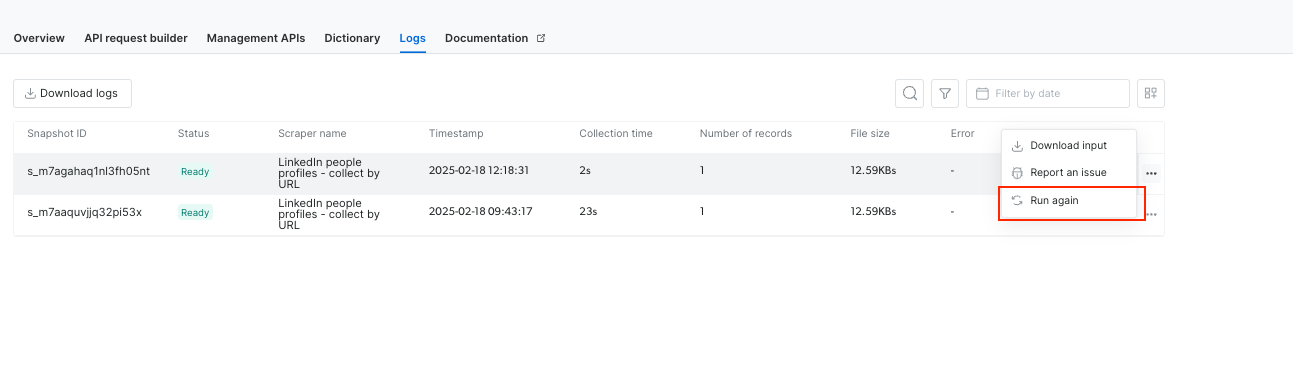
日志页面“再次运行”按钮 - 在日志页面添加“再次运行”按钮,允许用户单击即可重新运行相同请求,简化重试失败或历史任务的操作。
🚀 改进
- 我的抓取器表 - 当前运行的抓取器或最近使用的抓取器将显示在“我的抓取器”表顶部,更易于跟踪活跃任务,无需滚动查看已完成任务。
- WSA API - 为改善导航和组织,我们将“交付选项”部分移动到“管理 API”选项卡,使基于 API 的数据管理更加直观。
🐞 错误修复
- 无代码抓取器的收集任务失败时,用户现在可以下载错误详情,更好地理解问题原因。以前下载按钮被禁用,调试困难。此改进提高了透明度和排错效率。
- 修复“报告问题”功能未正确关联快照与工单的问题。现在,当客户报告问题时,正确的快照会自动关联,便于排查和解决问题。
代理产品:
🆕 新功能
- HTTP3 测试版已上线 - 代理网络升级以支持 HTTP3/QUIC 请求。如需体验,请联系 Bright Data 销售团队 - sales@brightdata.com
🚀 改进
- 在“概览”选项卡中更方便地 复制您的代理凭证,提供不同格式。
🐞 错误修复
- 修复账户管理 API 文档示例代码问题
- 补充缺失文档及部分旧文档链接无法正确跳转的问题
数据集:
🆕 新功能
-
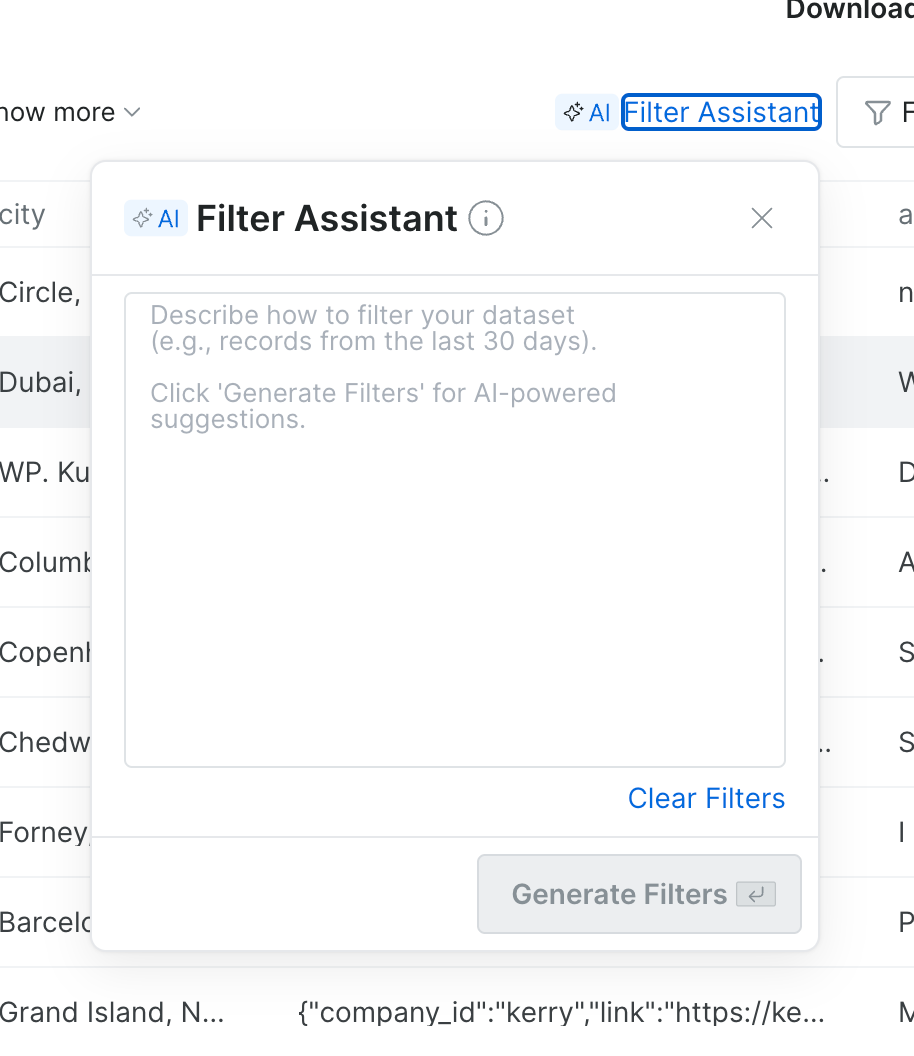
“AI 筛选助手” 允许用户使用 自然语言 筛选数据集——只需用英文描述所需过滤条件,即可获取相关记录。
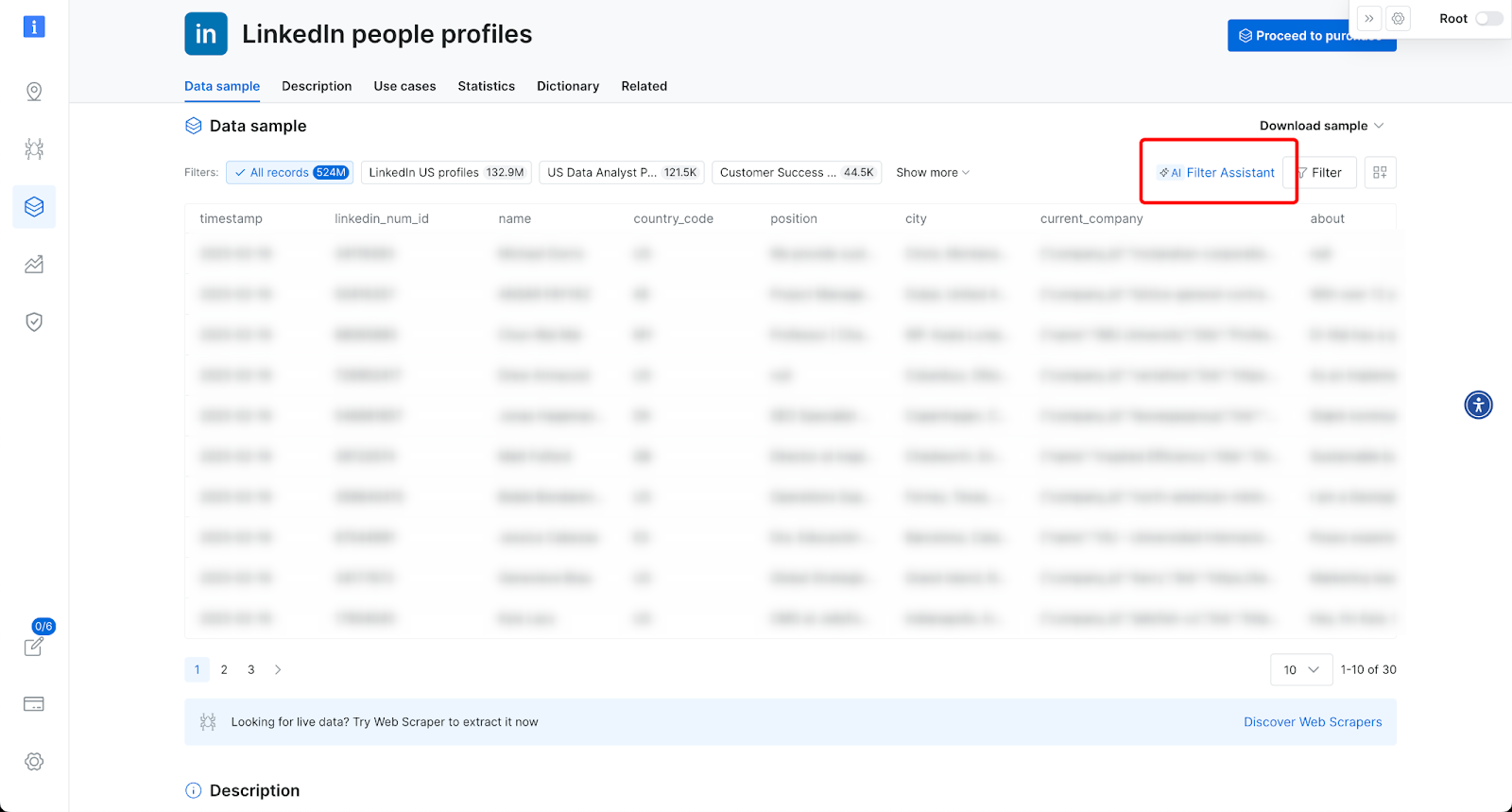
-
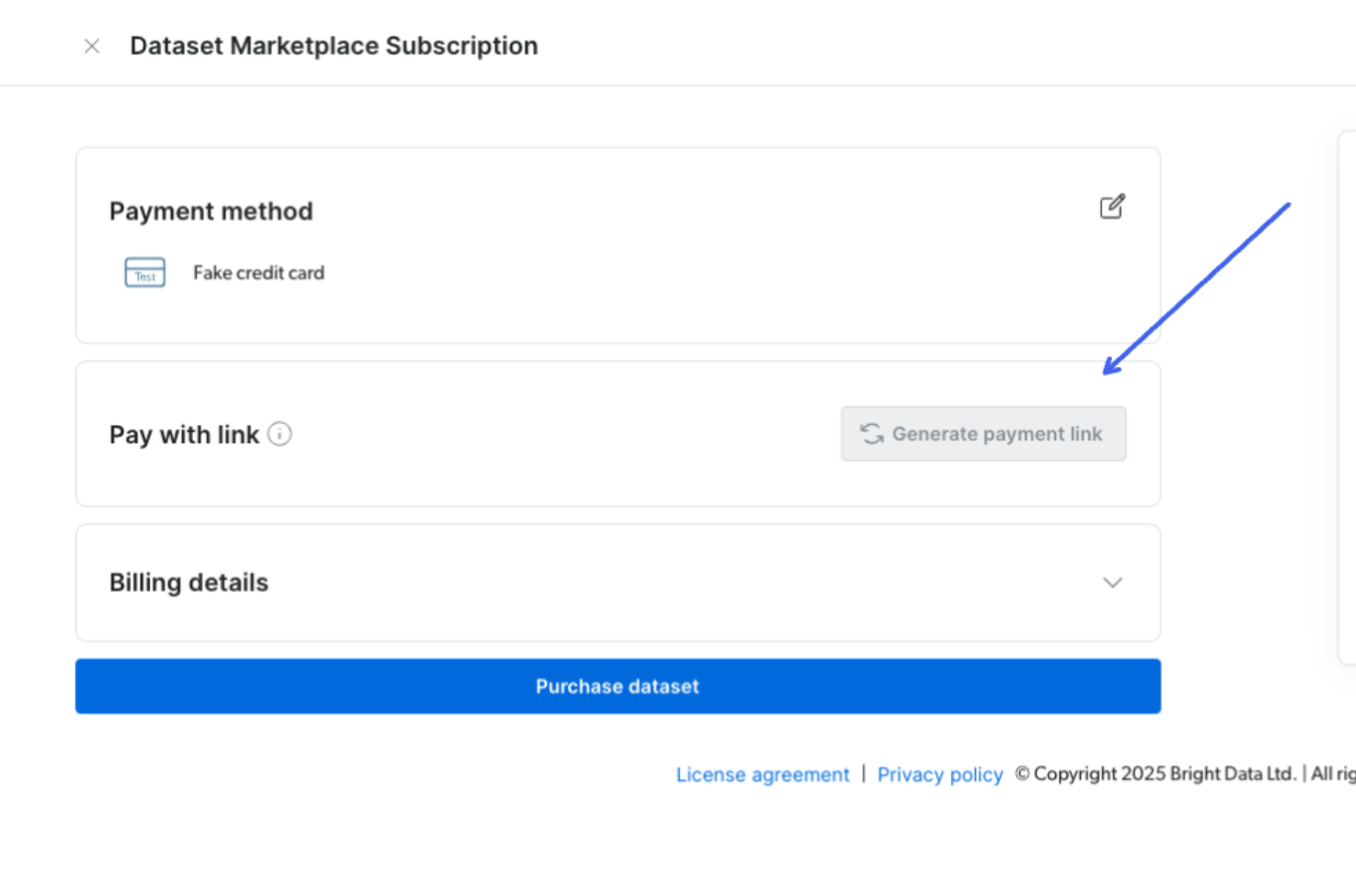
支付链接分享 – 仪表盘用户现在可以生成并分享支付链接,使其他人(如 CFO)无需登录控制面板即可完成购买。
-
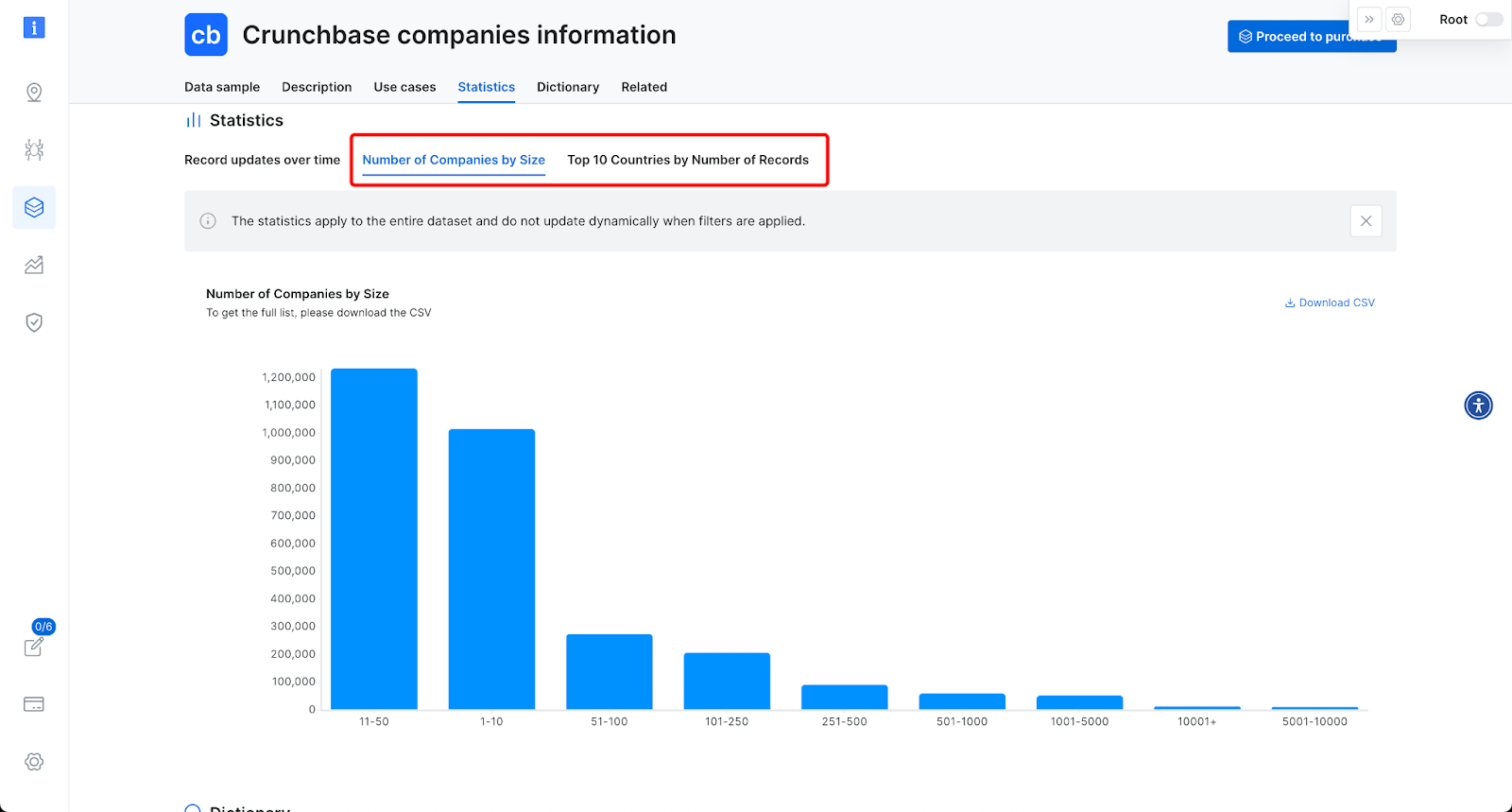
额外的数据集统计信息 – 每个数据集现在包括其内容的额外统计信息,例如:记录的地理分布。此信息每月更新。
🚀 改进
- 增强筛选体验 – 查看和优化过滤器及数据集时,可以移动过滤窗口,不再遮挡表格。
- 更好的数据样本预览 – 限制了单元格大小以提高可读性。用户现在可以点击字段展开并查看样本数据的完整数据点。
🐞 错误修复
- 修复上传 CSV 文件到过滤组件时解析错误的问题。
- 确保记录计数始终更新,以显示过滤效果。
抓取器:
🆕 新功能
- 自定义抓取器 - 允许用户在我们的市场中未提供域名时请求自定义抓取器。只需提供 2 个 URL 即可启动流程 - 观看视频
🚀 改进
- 自动邮件通知 - 客户首次触发抓取器后发送,以改善入门体验。
- 添加多语言代码示例 - 用户可以在所有 API 请求中以首选语言复制代码。
- “概览”标签页示例数量从 10 个减少到 5 个,为用户提供“清晰”视图。
- Sophie: 用户现在可以针对特定用例提问,并获得相关建议及直接的数据集链接。
🐞 错误修复
- 修复抓取器页面的损坏链接。